






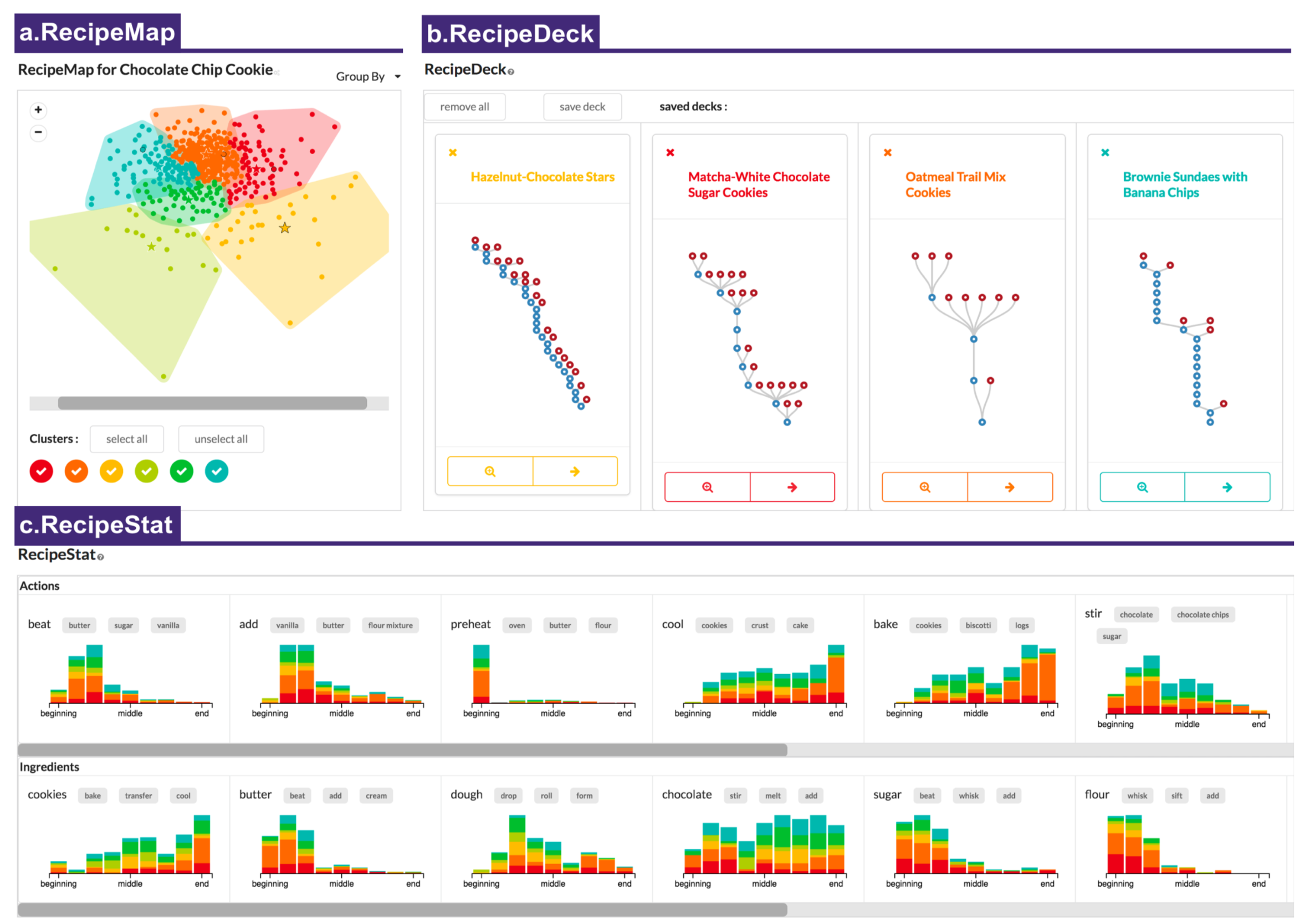
RecipeScape is an interface for analyzing cooking processes at scale with three main visualization components: (a) RecipeMap provides clusters of recipes with respect to their structural similarities (b) RecipeDeck provides in-depth view and pairwise comparisons of recipes (c) RecipeStat provides usage patterns of cooking actions and ingredients.

Computational Pipeline that uses Part-of-Speech tagger and human annotation to convert recipe text into a tree representation, and calculates pairwise distance to visualize the similarities.
Data Gathering: In the data gathering step, we crawl all search results for a
queried dish, like chocolate chip cookie and tomato pasta, from recipe websites that use
the schema.org’s Recipe scheme.
Parsing: We use off the shelf POS tagger and human annotation to parse tokens of the
crawled recipes. More detail is provided in the section below on annotation interface.
Similarity Comparison: In order to obtain similarities between the recipes, we use a
tree edit distance, a commonly used technique for comparing tree structures. However,
to incorporate the semantic difference between individual cooking actions and ingredients
in capturing the structural difference, we dynamically adjust the weights associated with
the relabel operations.
These weights are calculated using the cosine similarities of words from a pre-trained word
embedding model.
Distance Matrix: This similarity information is stored in a pairwise distance
matrix, where each element is the tree edit distance between the corresponding recipes. The
distance matrix is then converted into x,y coordinates using the Gram matrix.
Hierarchical Clustering: We used hierarchical clustering to group recipes with
procedural similarities.

Please cite our work if you use our annotated data!
recipes from "Chocolate Chip Cookie" query
recipes from "Tomato Pasta" query
Poster for HCI @ KAIST 2018 Winter Workshop
@inproceedings{chang2018recipescape,
title={RecipeScape: An Interactive Tool for Analyzing Cooking Instructions at Scale},
author={Chang, Minsuk and Guillain, L{\'e}onore V and Jung, Hyeungshik and Hare, Vivian M and Kim, Juho and Agrawala, Maneesh},
booktitle={Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems},
pages={451},
year={2018},
organization={ACM}
}
While our most recent paper is getting ready for publication, you can access our previous exploration here - Link to LBW Paper. The interface and the computational details have changed, but the overall approach is similar.
Slides for HCI@KAIST Workshop - 2017.02.02
@inproceedings{chang2017recipescape,
title={Recipescape: Mining and analyzing diverse processes in cooking recipes},
author={Chang, Minsuk and Hare, Vivian M and Kim, Juho and Agrawala, Maneesh},
booktitle={Proceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems},
pages={1524--1531},
year={2017},
organization={ACM}
}